Benchee
No podemos adivinar qué funciones son rápidas y cuáles son lentas - necesitamos medidas certeras cuando tenemos la curiosidad. Ahí es donde entran las pruebas de desempeño. En esta lección, vamos a aprender sobre cuan fácil es el medir la velocidad de nuestro código.
Sobre Benchee
Mientras existe una función en Erlang que puede ser utilizada para medidas simples del tiempo de ejecución de una función, no es tan agradable como lo es utilizar algunas de las otras herramientas disponibles y no te da las medidas necesarias para realizar estadísticas útiles. Es por ello que vamos a utilizar Benchee. Benchee nos proveé con una gama de estadísticas con comparaciones sencillas entre escenarios, una gran característica que nos permite hacer pruebas de distintas entradas para las funciones que estamos analizando, y varios formatos que podemos usar para visualizar nuestros resultados, así como la abilidad de escribir tu propio formato en caso de desearlo.
Uso
Para agregar Benchee a tu projecto, añádelo como una dependencia en tu archivo mix.exs:
defp deps do
[{:benchee, "~> 1.0", only: :dev}]
endDespués ejecutamos:
$ mix deps.get
...
$ mix compileEl primer comando descarga e instala Benchee. Es posible que se te pregunte si deseas instalar Hex. El segundo comando compila la aplicación Benchee. Ya estamos listos para escribir nuestro primer benchmark.
Una nota importante antes de comenzar: Cuando realizamos pruebas de desempeño, es importante no utilizar iex puesto que se comporta de forma distinta y comúnmente es mucho más lento que el código que se ejecuta en producción.
Entonces, procedemos a crear un archivo que llamaremos benchmark.exs, y en ese archivo vamos a añadir el siguiente código:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})Para correr nuestra prueba de desempeño, ejecutamos:
mix run benchmark.exsY debes ver algo como la siguiente salida en la terminal:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median 99th %
flat_map 2.40 K 416.00 μs ±12.88% 405.67 μs 718.61 μs
map.flatten 1.24 K 806.20 μs ±20.65% 752.52 μs 1186.28 μs
Comparison:
flat_map 2.40 K
map.flatten 1.24 K - 1.94x slower +390.20 μsPor supuesto, la información del sistema y los resultados pueden ser distintos dependiendo de las especificaciones de la máquina en la cuál estás haciendo las pruebas, pero esta información general debe estar ahí.
A primera vista, la sección Comparison nos muestra que nuestra versión map.flatten es 1.94x más lenta que flat_map. También nos dice que en promedio es alrededor de 390 microsegundos más lento, poniendo las cosas en perspectiva. ¡Es útil saber todo esto! Sin embargo, demos un vistazo a las demás estadísticas que tenemos:
- ips - significa “iteraciones por segundo”, que nos dice cuan seguido la función dada puede ser ejecutada en 1 segundo. Para esta métrica, un número grande es mejor.
- average - este es el tiempo de ejecución promedio de la función dada. Para esta métrica, un número menor es mejor.
- deviation - esta es la desviación estándar, que nos dice qué tanto los resultados varían en cada iteración. Aquí está dado como un porcentaje del promedio.
-
median - cuando se ordenan todos los tiempos medidos, este es el valor (o el promedio de los dos valores medios cuando el número de muestras es par).
Debido a inconsistencias del ambiente, este es más estable que
average, y en cierta medida es más probable que refleje el desempeño normal de tu código en producción. Para esta métrica, un número menor es mejor. - 99th % - 99% de todas las mediciones son más rápidas que esta, lo que la hace a esta algo cercano al desempeño en el peor escenario. Más bajo es mejor.
También hay otras estadísticas disponibles, pero estas cinco son frecuentemente las más útiles y más comúnmente usadas para las pruebas de desempeño, por lo que se muestran en el formato por defecto. Para aprender más sobre otras métricas disponibles, revisa la documentación en hexdocs.
Configuración
Uno de los mejores aspectos de Benchee es la gran cantidad de opciones de configuración. Vamos a revisar las opciones básicas primero dado que no requieren ejemplos de código, y después mostraremos cómo utilizar una de las mejores características de Benchee - entradas.
Nivel Básico
Benchee acepta una gran cantidad de opciones de configuración.
En la interfaz Benchee.run/2, estas se pasan como el segundo argumento en la forma de una lista de palabras clave opcional:
Benchee.run(%{"example function" => fn -> "hi!" end},
warmup: 4,
time: 10,
inputs: nil,
parallel: 1,
formatters: [Benchee.Formatters.Console],
print: [
benchmarking: true,
configuration: true,
fast_warning: true
],
console: [
comparison: true,
unit_scaling: :best
]
)Las opciones disponibles son las siguientes (también se encuentran documentadas en hexdocs).
- warmup - el tiempo (medido en segundos) por el que un escenario de pruebas debe ejecutarse sin realizar medidas, previo a que las medidas reales comiencen. Este parámetro simula un “calentamiento” previo. El valor por defecto es 2.
- time - el tiempo (medido en segundos) por el que un escenario de pruebas debe ejecutarse y medirse. El valor por defecto es 5.
- memory_time - el tiempo en segundos por el cual el consumo de memoria debe medirse para cada escenario de pruebas. Más tarde veremos más sobre esto. El valor por defecto es 0.
-
inputs - un mapa con cadenas de texto que representan el nombre de la entrada como llaves y las entradas como valor. También puede ser una lista de tuplas de la forma
{nombre_entrada, valor_real}El valor por defecto esnil(sin entradas). Vamos a cubrir esto en mayor detalle en la siguiente sección. -
parallel - el número de proceso que usar para las pruebas de desempeño de tus funciones.
Entonces, si declaras
parallel: 4, entonces se van a crear 4 procesos y cada uno ejecuta la misma función por el tiempo dado entime. Cuando estos terminan, entonces 4 nuevos procesos se crean para la siguiente función. Esto te da más información en el mismo tiempo, pero también pone una carga en el sistema que puede interferir con los resultados de las pruebas. Esto puede ser útil para simular un sistema bajo carga, lo que es en ocasiones útil, pero debe ser utilizado con precaución puesto que puede afectar los resultados de maneras impredecibles. El valor por defecto es 1 (que significa que no habrá ejecuciones en paralelo). -
formatters - una lista de formatos, ya sea cómo un módulo implementando el comportamiento de formateo, una tupla de tal módulo y las opciones que debe tomar, o funciones de formato. Son ejecutadas cuando usamos
Benchee.run/2. Las funciones deben aceptar un argumento (que es la información de la prueba de desempeño) y después usarlo para producir una salida. El valor por defecto es el formato de consolaBenchee.Formatters.Console. Vamos a cubrir esto en mayor detalle más adelante. -
measure_function_call_overhead - mide cuánto tiempo toma la llamada de una función vacía y lo resta al tiempo medido en cada prueba. Esto ayuda con la presición de pruebas muy rápidas. El valor por defecto es
true. -
pre_check - si correr o no cada trabajo con cada entrada - incluyendo todas las dadas con los hooks previos y posteriores a los escenarios o a las pruebas - antes de que las pruebas de desempeño son medidas para asegurar que nuestro código se ejecuta sin errores. Esto puede reducir tiempos durante el desarrollo de conjuntos de pruebas. El valor por defecto es
false. -
save - especifica un
pathdonde guardar los resultados del conjunto de pruebas actual, etiquetado con eltagespecificado. Más información en Guardando y Cargando en la documentación de Benchee. - load - carga un conjunto o conjuntos de pruebas guardados para comparar contra las pruebas actuales. Puede ser una cadena de texto o una lista de cadenas o patrones. Más informacion en Guardando y Cargando en la documentación de Benchee.
-
print - un mapa o lista de palabras clave con las siguientes opciones como átomos para las llaves y valores de
trueofalse. Esto nos permite controlar si la salida identificada por el átomo se imprime durante el proceso estándar de pruebas. Todas las opciones están habilitadas por defecto (true). Las opciones son:- benchmarking - imprime cuando Benchee comienza un nuevo trabajo de bechmarking.
- configuration - un resumen de las opciones de configuración incluyendo el tiempo estimado total de ejecución que se imprime previo a que comiencen las pruebas.
- fast_warning - las advertencias se despliegan si las funciones son ejecutadas muy rápido, potencialmente causando mediciones imprecisas.
-
unit_scaling - la estrategia para elegir una medida para la duración y conteos.
Al escalar un valor, Benchee encuentra la unidad “más apropiada” (la más grande para la cual el resultado es al menos 1).
Por ejemplo,
1_200_000se escala a 1.2 M mientras que800_000se escala a 800 K. La estrategia de escalación de unidades determina cómo elige Benchee la más apropiada para la lista entera de valores, mientras que los valores en la lista pueden tener unidades más apropiadas distintas. Existen 4 estrategias, todas dadas como átomos, con:bestcomo el valor por defecto:- best - la medida que aparece con mayor frecuencia es utilizada. Un empate resulta en que se utilice la unidad más grande.
- largest - se utiliza la unidad apropiada más grande.
- smallest - se utiliza la unidad apropiada más pequeña.
- none - no ocurre escalamiento de unidades. Las duraciones se despliegan en nanosegundos, y los conteos de iteraciones por segundo se despliegan sin unidades.
-
:before_scenario/after_scenario/before_each/after_each- no entraremos en gran detalle aquí, pero si necesitas realizar algo antes/después de tu función de análisis de desempeño, sin que esto se cuente en la medición puedes revisar la sección de hooks de Benchee.
Entradas
Es importante analizar el desempeño de funciones con datos que reflejen lo que una función realmente podría operar en el mundo real.
¡Frecuentemente una función se puede comportar distinto con conjuntos pequeños de datos contra conjuntos grandes! Es por esto que tenemos la opción de configuración inputs.
Esta nos permite realizar pruebas de la misma función con tantas entradas distintas como uno deseé, y después puedes ver el resultado de las pruebas con cada una de esas funciones.
Veamos nuevamente nuestro ejemplo original:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})En ese ejemplo estamos usando solo una única lista con enteros desde el 1 al 10,000. Vamos a actualizarla para utilizar entradas completamente distintas para que podamos ver lo que sucede con listas pequeñas y grandes. Entonces, abre ese archivo, y vamos a cambiarlo para lucir como el siguiente:
map_fun = fn i -> [i, i * i] end
inputs = %{
"small list" => Enum.to_list(1..100),
"medium list" => Enum.to_list(1..10_000),
"large list" => Enum.to_list(1..1_000_000)
}
Benchee.run(
%{
"flat_map" => fn list -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn list -> list |> Enum.map(map_fun) |> List.flatten() end
},
inputs: inputs
)
Vas a notar 2 diferencias.
Primero, ahora tenemos un mapa inputs que contiene la información para cada entrada a nuestras funciones.
Estamos pasando ese mapa de entradas como una opción de configuración a Benchee.run/2.
Y puesto que ahora nuestras funciones necesitan tomar un argumento,necesitamos actualizar nuestras funciones de pruebas para aceptar un argumento. Entonces, en vez de:
fn -> Enum.flat_map(list, map_fun) endahora tenemos:
fn list -> Enum.flat_map(list, map_fun) endEjecutemos esto nuevamente usando:
mix run benchmark.exsAhora deberías ver una salida en tu consola como la siguiente:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: large list, medium list, small list
Estimated total run time: 42 s
Benchmarking flat_map with input large list...
Benchmarking flat_map with input medium list...
Benchmarking flat_map with input small list...
Benchmarking map.flatten with input large list...
Benchmarking map.flatten with input medium list...
Benchmarking map.flatten with input small list...
##### With input large list #####
Name ips average deviation median 99th %
flat_map 13.20 75.78 ms ±25.15% 71.89 ms 113.61 ms
map.flatten 10.48 95.44 ms ±19.26% 96.79 ms 134.43 ms
Comparison:
flat_map 13.20
map.flatten 10.48 - 1.26x slower +19.67 ms
##### With input medium list #####
Name ips average deviation median 99th %
flat_map 2.66 K 376.04 μs ±23.72% 347.29 μs 678.17 μs
map.flatten 1.75 K 573.01 μs ±27.12% 512.48 μs 1076.27 μs
Comparison:
flat_map 2.66 K
map.flatten 1.75 K - 1.52x slower +196.98 μs
##### With input small list #####
Name ips average deviation median 99th %
flat_map 266.52 K 3.75 μs ±254.26% 3.47 μs 7.29 μs
map.flatten 178.18 K 5.61 μs ±196.80% 5.00 μs 10.87 μs
Comparison:
flat_map 266.52 K
map.flatten 178.18 K - 1.50x slower +1.86 μsAhora podemos ver información para nuestras pruebas de desempeño, agrupadas por entrada. Este ejemplo simple no proveé ningún tipo de conocimiento sorprendente, ¡pero te sorprenderá saber cuánto varía el desempeño con base en el tamaño de la entrada!
Formatos
La salida en terminal que hemos visto hasta ahora es útil para comenzar a medir el tiempo de ejecución de nuestras funciones, ¡pero no es nuestra única opción! En esta sección vamos a ver brevemento otros tres tipos de formatos disponibles, y también tocaremos qué necesitas para escribir tu propio formato si lo deseas.
Otros formatos
Benchee incluye un formato de consola, que es el que hemos visto ya, pero hay otros tres formatos con soporte oficial -
benchee_csv,
benchee_json y
benchee_html.
Cada uno de ellos hace exactamente lo que uno esperaría, que es escribir los resultados a sus respectivos formatos de archivo para que puedas trabajar con los resultados en el formato que prefieres.
Cada uno de estos formatos es un paquete separado, por lo que para usarlo debes agregarlo como una dependencia a tu archivo mix.exs así:
defp deps do
[
{:benchee_csv, "~> 1.0", only: :dev},
{:benchee_json, "~> 1.0", only: :dev},
{:benchee_html, "~> 1.0", only: :dev}
]
end
Mientras que benchee_json y benchee_csv son simples, benchee_html tiene muchas funcionalidades.
Te puede ayudar a producir fácilmente gráficas de resultados, e incluso las puedes exportar como imágenes PNG.
Puedes revisar un reporte HTML de ejemplo si te interesa. Incluye gráficas como esta:
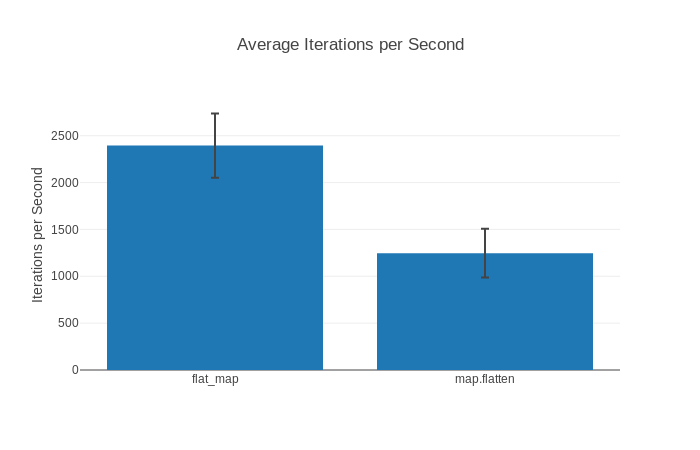
Los 3 formatos están bien documentados en sus respectivas páginas de GitHub, por lo que no los cubriremos a detalle aquí.
Formatos personalizados
Si los cuatro formatos ofrecidos no son suficientes para ti, también puedes escribir tu propio formato.
Escribir un formato es bastante sencillo.
Debes escribir una función que acepta una estructura %Benchee.Suite{}, y a partir de ella puedes obtener cualquier información que te interese.
Puedes encontrar información sobre lo que hay en esta estructura en GitHub o en HexDocs.
El código fuente está bien documentado y es fácil de leer, en caso de que quieras ver qué tipo de información puede estar disponible para escribir formatos personalizados.
También puedes escribir un formato más complejo que adopta el comportamiento de Benchee.Formatter. Nos vamos a quedar con la versión de función sencilla aquí.
Por ahora, vamos a ver un ejemplo rápido de cómo se vería un formato, como ejemplo de lo sencillo que es. Digamos que solo queremos un formato extremadamente minimalista que imprime el tiempo promedio de ejecución para cada escenario - puede lucir como el siguiente:
defmodule Custom.Formatter do
def output(suite) do
suite
|> format
|> IO.write()
suite
end
defp format(suite) do
Enum.map_join(suite.scenarios, "\n", fn scenario ->
"Average for #{scenario.job_name}: #{scenario.run_time_data.statistics.average}"
end)
end
endY entonces podemos correr nuestra prueba así:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
formatters: [&Custom.Formatter.output/1]
)Y cuando corremos ahora con nuestro formato personalizado, podemos ver:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Average for flat_map: 419433.3593474056
Average for map.flatten: 788524.9366408596Memoria
Casi hemos llegado al final, pero hemos llegado hasta aquí sin mostrar una de las características más interesantes de Benchee: ¡medidas de memoria!
Benchee es capaz de medir el consumo de memoria, aunque es limitado al proceso en que tu prueba de desempeño se ejecuta. Actualmente no puede supervisar el consumo de memoria en otros procesos (como pools de workers).
El consumo de memoria incluye toda la memoria utilizada en tu escenario de pruebas - también la memoria que fue recolectada por el recolector de basura, por lo que no necesariamente representa el tamaño máximo de memoria por proceso.
¿Cómo lo usamos? ¡Simplemente con la opción :memory_time!
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 0 ns
time: 0 ns
memory time: 1 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking flat_map...
Benchmarking map.flatten...
Memory usage statistics:
Name Memory usage
flat_map 624.97 KB
map.flatten 781.25 KB - 1.25x memory usage +156.28 KB
**All measurements for memory usage were the same**Como puedes ver, Benchee no se preocupa por mostrar todas las estadísticas dado que todas las pruebas tomadas fueron iguales. Esto es de hecho bastante común si tus funciones no incluyen algo de aleatoriedad. Y ¿qué utilidad tendrían todas las estadísticas si simplemente te dieran el mismo número todo el tiempo?
¿Encontraste un error o quieres contribuir a la lección? ¡Edita esta lección en GitHub!