Benchee
我们不能简单地猜测哪个函数运行得快,哪个慢 - 而是需要实际的测量值。这就是需要基准测量介入的时候了。本课程将学习如何度量代码的执行效率。
关于 Benchee
虽然有一个Erlang 函数 可以测量函数的运行时间,但是它并不如一些工具好用。而且,它不能通过多次测量获得好的统计数字。所以,我们可以使用 Benchee。Benchee 提供了不同场景下的统计数字的比较功能。这个功能可以让我们测试函数不同的输入参数。Benchee 还有不同的格式化工具显示比较结果,你甚至可以写自己的格式化工具。
使用
把 Benchee 作为依赖添加到你的 mix.exs 文件:
defp deps do
[{:benchee, "~> 1.0", only: :dev}]
end然后执行:
$ mix deps.get
...
$ mix compile第一个命令会下载和安装 Benchee。或许你还会同时被要求安装 Hex。第二个命令编译 Benchee 应用。这样我们就可以写第一个基准测试了!
开始前的注意事项: 开始基准测试的时候,最重要的是别使用 iex 因为它的行为是不一样给的,也比线上运行的速度要慢很多。所以,我们先创建名为 benchmark.exs 的基准测试文件,并在里面添加以下代码:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})现在就可以运行我们的基准测试了:
mix run benchmark.exs类似的输出就会出现在你的命令行控制台:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median 99th %
flat_map 2.40 K 416.00 μs ±12.88% 405.67 μs 718.61 μs
map.flatten 1.24 K 806.20 μs ±20.65% 752.52 μs 1186.28 μs
Comparison:
flat_map 2.40 K
map.flatten 1.24 K - 1.94x slower +390.20 μs当然,你的系统信息和比较结果应该会和这里不一样,因为运行基准测试的机器配置不同,但是基本的信息应该都在。
一眼看过去,Comparison 部分显示 map.flatten 比 flat_map 慢 1.94 倍,还显示了平均慢了 390 微秒。 - 这些信息是多么有帮助!让我们再看一下其它统计信息:
- ips - 全称是 “iterations per second”。它告诉了我们每秒当前函数可以被调用多少次。对于这个数字,越大越好。
- average - 给定函数的平均执行时间。这个数值越小越好。
- deviation - 这是标准差,也就是每次调用耗时和前述平均值之间的偏移量。这里是平均标准差的百分比形式。
-
median - 中位数。当所有的数值都测量出来后,排序,取中间的那个值(如果是偶数结果的话,取中间两个值的平均数)。因为环境的不一致性,这个值比
average更稳定,也更能体现代码在线上运行的效率。这个数值也是越小越好。 - 99th % - 99% 的测量值比当前数值要快,也就是说这个基本是最差的性能指标。这个数值越小越好。
还有其它的一些统计数字,但是这四个是最常用,也是最常用的测量基准值,所以它们都在默认的格式化工具中显示。想了解更多可用的测量数值,可参考 hexdocs 上的文档。
配置
Benchee 的可用配置选项非常强大。我们先过一下基本设置,因为它们不需要代码展示。然后我们再看看 Benchee 其中一个最赞的功能 - 输入。
基本配置
Benchee 的配置选项非常丰富。对于最常用的 Benchee.run/2 接口,下面是可选的第二个参数的关键字列表所支持的配置:
Benchee.run(%{"example function" => fn -> "hi!" end},
warmup: 4,
time: 10,
inputs: nil,
parallel: 1,
formatters: [Benchee.Formatters.Console],
print: [
benchmarking: true,
configuration: true,
fast_warning: true
],
console: [
comparison: true,
unit_scaling: :best
]
)以下就是支持的选项(文档也在 hexdocs).
- warmup - 热身时间(以秒为单位)。基准测量在真正计算运行时间前先进行一段时间的热身。这是为了模拟一个已经热身的运行系统。默认值为两秒。
- time - 基准测量时间(以秒为单位),也就是每次基准测试的运行和测量时间。默认值为五秒。
- memory_time - the time in seconds for how long memory consumption should be measured for every benchmarking scenario. We’ll look at that later. Defaults to 0.
-
inputs - 一个以字符串为键,实际输入为值的映射。也可以是以
{input_name, actual_value}格式的元组列表。默认值为nil。我们在下一章会详细解释这个参数。 -
parallel - 并行基准测试运行时,使用的进程数。如果你设置了
parallel: 4,那么,就会创建 4 个进程来在给定的time时间内执行相同的函数。完成后,又会创建 4 个新的进程执行下一个函数。使用这个选项虽然能得到更多的数据,但是同时也让系统增加压力,可能会干扰基准测试的结果。在需要测试压力下系统的表现时,这个参数有时还是有用的。但是,必须谨慎使用,因为它可能会以意想不到的方式影响测试结果。默认值为 1(也就是没有并行执行测试)。 -
formatters - 格式化函数列表。列表里既可以是实现了 formatter 行为的模块,或上述模块以及相应参数组成的元组,又或者只是 formatter 函数。在运行
Benchee.run/2时,应用于基准测试结果。这些函数都应该接收一个参数(基准测试数据集),并产生最后输出结果。默认是内置的命令行控制台格式化工具,Benchee.Formatters.Console。后面的章节会更详细介绍这部分。 -
measure_function_call_overhead - 测量一个空函数调用的时间,然后由此推断每次运行时间。对于一些非常短的基准数据测量时很有用。默认值为
true。 -
pre_check - 在测量前是否使用各自的入参来执行每一个任务,包含每个给定的前后置场景或者每个钩子 - 确保你的代码没有任何问题。当你开发自己的套件时,可以帮你节省时间。默认值为
false。 -
save - 为当前基准测量结果指定结果保存路径
path,并用tag打上标记。详见 Benchee 文档的保存和加载。 - load - 加载一个之前保存的一个或多个基准测量结果来和当前的比较。可以是一个字符串,也可以是字符串或匹配规则的列表。详见 Benchee 文档的保存和加载。
-
print - 一个映射或者关键字列表,以配置项原子作为键,
true或者false为值。这个控制了原子键对应的输出选项是否在标准的基准测试运行中打印出来。所有的选项默认都是打开的(true)。支持的选项有:- benchmarking - Benchee 开始一个新的基准测试任务时打印。
- configuration - 基准测试的配置选项总结,包括预计总运行时间。在测试前打印。
- fast_warning - 当函数执行速度太快时显示出来的警告,因为有可能导致不准确的测量结果。
-
unit_scaling - 选择时间和数量单位刻度的策略。Benchee 会尝试选择最佳的单位来显示一个值(结果中最大的值的单位应该最少是 1).比如,
1_200_000会被显示为 1.2 M,而800_000则会被显示为 800 K。单位的伸缩策略决定了 Benchee 如何选择适应整个列表值的最佳单位,尤其是列表中不同的值有不同的最佳单位时。一共有四个策略,都以原子表示,默认是:best:- best - 使用最常用的最佳单位。打平时会选择大的单位。
- largest - 使用最大的最佳单位。
- smallest - 使用最小的最佳单位。
- none - 不适用任何的伸缩调节。时间按照毫微秒来显示,ips 数量则不显示单位。
-
:before_scenario/after_scenario/before_each/after_each- 我们不会深入讲解这几个设置。如果你希望在基准测量函数运行前后做写额外的事情,但又不把这部分的时间计算在内,请参看 Benchee 文档的 hooks 章节
输入
使用那些实际可能出现的数据,来基准测试一个函数是非常重要的。大多数的情况下,一个函数在大数据集,和小数据集下的行为表现是很不同的!这就是 Benchee 的 inputs 配置选项起作用的地方。它允许你使用自选的各种数据来测试同一个函数,然后就能看到各自的结果。
让我们看看原来的例子:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})这个例子中,我们只是使用了从 1 到 10,000 的整数列表。让我们使用几个不同的输入,看看大小不同的列表会有什么表现。我们可以把代码修改为下面的样子:
map_fun = fn i -> [i, i * i] end
inputs = %{
"small list" => Enum.to_list(1..100),
"medium list" => Enum.to_list(1..10_000),
"large list" => Enum.to_list(1..1_000_000)
}
Benchee.run(
%{
"flat_map" => fn list -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn list -> list |> Enum.map(map_fun) |> List.flatten() end
},
inputs: inputs
)
你会注意到这里有两个不同。首先,我们现在有了一个 inputs 映射,包含了函数的输入。这个 inputs 映射会作为配置参数传给 Benchee.run/2。
并且,因为现在我们的函数需要接收一个参数,我们需要更新基准测试函数,与其:
fn -> Enum.flat_map(list, map_fun) end我们现在要改为:
fn list -> Enum.flat_map(list, map_fun) end让我们再做一次测试:
mix run benchmark.exs现在你应该在控制台看到类似这样的输出:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: large list, medium list, small list
Estimated total run time: 42 s
Benchmarking flat_map with input large list...
Benchmarking flat_map with input medium list...
Benchmarking flat_map with input small list...
Benchmarking map.flatten with input large list...
Benchmarking map.flatten with input medium list...
Benchmarking map.flatten with input small list...
##### With input large list #####
Name ips average deviation median 99th %
flat_map 13.20 75.78 ms ±25.15% 71.89 ms 113.61 ms
map.flatten 10.48 95.44 ms ±19.26% 96.79 ms 134.43 ms
Comparison:
flat_map 13.20
map.flatten 10.48 - 1.26x slower +19.67 ms
##### With input medium list #####
Name ips average deviation median 99th %
flat_map 2.66 K 376.04 μs ±23.72% 347.29 μs 678.17 μs
map.flatten 1.75 K 573.01 μs ±27.12% 512.48 μs 1076.27 μs
Comparison:
flat_map 2.66 K
map.flatten 1.75 K - 1.52x slower +196.98 μs
##### With input small list #####
Name ips average deviation median 99th %
flat_map 266.52 K 3.75 μs ±254.26% 3.47 μs 7.29 μs
map.flatten 178.18 K 5.61 μs ±196.80% 5.00 μs 10.87 μs
Comparison:
flat_map 266.52 K
map.flatten 178.18 K - 1.50x slower +1.86 μs现在,我们的基准测试按照 input 分组了。虽然这个简单的例子并不能得出多深入的见解,但是你应该注意到,性能随着输入数据集的大小变化有多大!
格式化工具
控制台的输出对于测量函数的运行时间非常有帮助,也易于使用。但是,这并不代表是唯一的选择!本章我们将粗略地看看其它三个格式化输出工具,并了解如何才能写自己的格式化工具。
其它格式化工具
Benchee 默认集成的是控制台的格式化输出工具,但是,还有其它三个官方支持的工具 - benchee_csv,
benchee_json 和 benchee_html。每个都和期望的那样,把结果写到特定格式的文件,然后你可以再进一步处理。
每一个格式化工具都是独立的包,所以,必须把它们添加到 mix.exs 中作为依赖才能使用:
defp deps do
[
{:benchee_csv, "~> 1.0", only: :dev},
{:benchee_json, "~> 1.0", only: :dev},
{:benchee_html, "~> 1.0", only: :dev}
]
end
benchee_json 和 benchee_csv 非常简单,而 benchee_html 则实际上_相当_功能丰富!它很容易就能让你生成漂亮的图表。你还能导出为 PNG 图片。如果感兴趣,你可以查看这个html 报告样例,它包含了类似下面的图表:
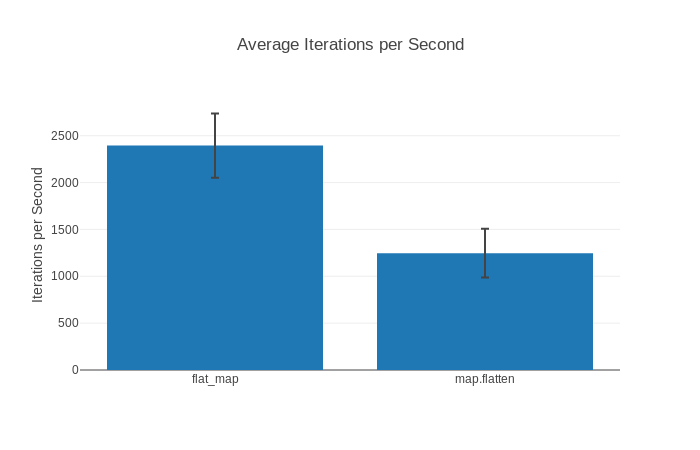
这三个格式化工具的文档都详细记录在它们各自的 Github 主页上,所以我们就不详细说明了。
自定义格式化工具
如果提供的四个格式化工具都不足以满足你的需求,你还可以自己写一个。写一个格式化工具相当的容易。你只需要提供一个接收 %Benchee.Suite{} 结构体的函数,然后就可以从中获取任何想要的信息。你可以查看 GitHub 或者 HexDocs 来了解结构体里面到底有什么信息。代码都有相当完善的注释易读。如果你想自己实现一个格式化工具,查看有什么信息在里面也不难。
你也可以写一个全功能的,实现了 Benchee.Formatter 行为的格式化组件,但是我们这里还是以介绍简单的函数版本为主。
这里,我就简单地展示一个自定义的格式化工具长什么样,并且多容易实现。假设我们仅仅想要最少的数据,只是打印出每个场景的平均运行时间。下面是代码样例:
defmodule Custom.Formatter do
def output(suite) do
suite
|> format
|> IO.write()
suite
end
defp format(suite) do
Enum.map_join(suite.scenarios, "\n", fn scenario ->
"Average for #{scenario.job_name}: #{scenario.run_time_data.statistics.average}"
end)
end
end然后我们可以这样运行测试:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
formatters: [&Custom.Formatter.output/1]
)然后我们的测试结果,就会按照自定义的格式化工具显示成:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Average for flat_map: 419433.3593474056
Average for map.flatten: 788524.9366408596内存
本教程也快要结束了,但是我们还没有给你展示 Benchee 最拉风的功能,内存测量!
Benchee 可以测量内存使用量,不过它仅限于你的基准测试当前的执行进程。它无法跟踪测量其它进程的内存消耗(比如 worker 工作进程池)。
内存消耗包括了基准测试场景使用了的所有内存,同时包含了那些被垃圾回收的内存。所以,它并不代表进程所消耗的最大内存值。
怎么使用这个功能呢?只需要添加 :memory_time 这个配置就可以了!
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 0 ns
time: 0 ns
memory time: 1 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking flat_map...
Benchmarking map.flatten...
Memory usage statistics:
Name Memory usage
flat_map 624.97 KB
map.flatten 781.25 KB - 1.25x memory usage +156.28 KB
**All measurements for memory usage were the same**如你所见,Benchee 并不会展示所有统计值,因为所有的测试样本都是一样的。如果你的函数并不包含一定的随机性的话,这很正常。那如果它总是告诉你同一个数字,这样的统计好处在哪里呢?
Caught a mistake or want to contribute to the lesson? Edit this lesson on GitHub!