Benchee
Não podemos simplesmente adivinhar quais funções são rápidas e quais são lentas - precisamos de medidas reais quando estamos curiosos. É aí que benchmarking entra. Nesta lição, aprenderemos sobre como é fácil medir a velocidade do nosso código.
Sobre Benchee
Enquanto existe uma função no Erlang que pode ser usada para medição muito básica do tempo de execução de uma função, ela não é tão boa de usar como algumas das ferramentas disponíveis e não lhe dá várias medidas para obter boas estatísticas, então vamos usar Benchee. Benchee nos fornece uma série de estatísticas com comparações fáceis entre cenários, uma ótima característica que nos permite testar diferentes entradas para as funções que estamos avaliando, e vários formatadores diferentes que podemos usar para mostrar nossos resultados, assim como a capacidade de escrever seu próprio formatador se desejado.
Uso
Para adicionar Benchee ao seu projeto, adicione-o como uma dependência ao seu arquivo mix.exs:
defp deps do
[{:benchee, "~> 1.0", only: :dev}]
endEntão chamamos:
$ mix deps.get
...
$ mix compileO primeiro comando vai baixar e instalar o Benchee. Você pode ser solicitado a instalar o Hex junto com ele. O segundo compila a aplicação Benchee. Agora estamos prontos para escrever nosso primeiro benchmark!
Uma nota importante antes de começarmos: Quando avaliar comparativamente, é muito importante não usar iex uma vez que isso funciona de forma diferente e é frequentemente muito mais lento do que seu código usado em produção. Então, vamos criar um arquivo que chamaremos benchmark.exs, e nesse arquivo vamos adicionar o seguinte código.
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})Agora para executar nosso benchmark, chamamos:
mix run benchmark.exsE devemos ver algo com a seguinte saída no seu console:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median 99th %
flat_map 2.40 K 416.00 μs ±12.88% 405.67 μs 718.61 μs
map.flatten 1.24 K 806.20 μs ±20.65% 752.52 μs 1186.28 μs
Comparison:
flat_map 2.40 K
map.flatten 1.24 K - 1.94x slower +390.20 μsÉ claro que as informações e os resultados do seu sistema podem ser diferentes dependendo das especificações da máquina em que você está executando seus benchmarks, mas esta informação geral deve estar toda lá.
À primeira vista, a seção Comparison nos mostra que a versão do nosso map.flatten é 1.94x mais lenta do que flat_map. E também mostra que, em média, é cerca de 390 microssegundos mais lento, o que coloca as coisas em perspectiva. Isso é útil saber! No entanto, vamos olhar para as outras estatísticas que temos:
- ips - isso significa “iterações por segundo”, que nos diz com que frequência a função pode ser executada em um segundo. Para esta métrica, um número maior é melhor.
- average - este é o tempo médio de execução da função. Para esta métrica, um número baixo é melhor.
- deviation - este é o desvio padrão, que nos diz o quanto os resultados para cada iteração variam nos resultados. Aqui é dado como uma porcentagem da média.
-
median - quando todos tempos medidos são ordenados, este é o valor médio (ou média dos dois valores do meio quando o número de amostras é par). Devido à inconsistências de ambiente este será mais estável do que a
average, e um pouco mais provável que reflita a performance normal do seu código em produção. Para esta métrica, um número baixo é melhor. - 99th% - 99% de todas as medições são mais rápidas do que isto, o que torna este tipo como pior caso de desempenho. Menor é melhor.
Há também outras estatísticas disponíveis, mas estas quatro são frequentemente as mais úteis e comumente usadas para benchmarking, por isso elas são exibidas no formatador padrão. Para aprender mais sobre outras métricas disponíveis, confira a documentação hexdocs.
Configuração
Uma das melhores partes do Benchee são todas as opções de configuração disponíveis. Examinaremos o básico primeiro, uma vez que não requerem exemplos de código, e então mostraremos como usar uma das melhores características do Benchee - inputs.
Básico
Benchee possui uma grande variedade de opções de configuração. Na interface mais comum Benchee.run/2, estas são passadas como segundo argumento na forma de uma keywork list opcional:
Benchee.run(%{"example function" => fn -> "hi!" end},
warmup: 4,
time: 10,
inputs: nil,
parallel: 1,
formatters: [Benchee.Formatters.Console],
print: [
benchmarking: true,
configuration: true,
fast_warning: true
],
console: [
comparison: true,
unit_scaling: :best
]
)As opções disponíveis são as seguintes (também documentadas em hexdocs).
- warmup - o tempo em segundos para o qual um cenário de benchmarking deve ser executado sem tempos de medição antes do início das medidas reais. Isso simula um sistema de funcionamento “quente”. Padrão é 2.
- time - o tempo em segundos por quanto tempo cada cenário de benchmarking individual deve ser executado e medido. Padrão é 5.
- memory_time - o tempo em segundos de quanto tempo o consumo de memória deve ser medido para cada cenário do benchmarking. Veremos isso mais tarde. O padrão é 0.
-
inputs - um mapa com strings que representam o nome da entrada como as chaves e a entrada real como os valores. Também pode ser uma lista de tuplas no formato
{input_name, actual_value}. O padrão énil(sem entradas). Vamos cobrir isso em detalhes na próxima seção. -
parallel - o número de processos para usar no benchmark de suas funções. Então, se você definir
parallel: 4, serão gerados 4 processos que executam a mesma função para determinadotime. Quando estes terminam, então 4 novos processos serão gerados para a próxima função. Isso lhe dá mais dados no mesmo tempo, mas também adiciona mais carga ao sistema interferindo nos resultados do benchmark. Isso pode ser útil para simular um sistema sobrecarregado, o que algumas vezes é útil, mas deve ser usado com algum cuidado pois isso pode afetar os resultados de maneiras imprevisíveis. Padrão é 1 (o que significa nenhuma execução em paralelo). -
formatters - uma lista de formatadores podendo ser um módulo implementando o comportamento do formatador, uma tupla do referido módulo e opções que ele deve tomar ou funções formatadoras. Eles são executados ao usar
Benchee.run/2. Funções precisam aceitar um argumento (que é o conjunto de benchmarking com todos os dados) e então usar isso para produzir a saída. O padrão é o formatador de console embutido noBenchee.Formatters.Console. Nós cobriremos isso mais em uma seção posterior. - measure_function_call_overhead - mensurar quanto tempo uma chamada de função vazia leva e deduza isso de cada tempo de execução medido. Ajuda com a precisão de benchmarks muito rápidos. O padrão é true.
- pre_check - se deve ou não executar cada tarefa com cada entrada - incluindo tudo antes ou depois do cenário ou de cada hook - antes que os benchmarks sejam medidos para garantir que seu código seja executado sem erro. Isso pode economizar tempo ao desenvolver suas suítes. O padrão é false.
-
save - especificar um caminho onde armazenar os resultados da suite de benchmarks atual, marcado com a
tagespecificada. Consulte Salvando & Carregando nos documentos do Benchee. - load - carregar uma suite ou suites gravadas para comparar os seus valores de referência atuais. Poderá ser uma string ou uma lista de strings ou patterns. Consulte Salvando e Carregando nos documentos do Benchee.
-
print - um map ou keyword list com as seguintes opções como átomos para as chaves e valores de
trueoufalse. Isso nos permite controlar se a saída identificada pelo átomo será impressa durante o processo padrão de benchmarking. Todas as opções são habilitadas por padrão (true). Opções são:- benchmarking - imprime quando Benchee inicia o benchmarking de um novo job.
- configuration - um resumo de opções de benchmarking configuradas, incluindo o tempo total de execução estimado. Isso é impresso antes do benchmarking iniciar.
- fast_warning - avisos são mostrados se funções são executadas muito rapidamente, potencialmente levando a medidas imprecisas.
-
unit_scaling - a estratégia para escolher uma unidade para durações e contagens. Ao dimensionar um valor, Benchee encontra a unidade de “best fit” (a maior unidade para qual o resultado é ao menos 1). Por exemplo,
1_200_000escala até 1.2 M, enquanto800_000escala até 800 K. A estratégia de escala da unidade determina como Benchee escolhe a unidade de “best fit” para uma lista inteira de valores, quando os valores individualmente na lista podem ter diferentes unidades de “best fit”. Existem quatro estratégias, todas dadas como átomos, padronizadas como:best:- best - a mais frequente unidade de best fit será usada. Um empate resultará na maior unidade sendo selecionada.
- largest - a maior unidade de best fit será usada
- smallest - a menor unidade de best fit será usada
- none - nenhuma escala de unidade ocorrerá. Durações serão mostradas em microsegundos, e contadores de ips serão mostrados sem unidades.
-
:before_scenario/after_scenario/before_each/after_each- nós não vamos nos prolongar muito nesse aqui, mas se você precisa fazer algo antes/depois da sua função de benchmarking sem que seja mensurado consulte a seção de hooks na documentação do Benchee.
Inputs
É muito importante fazer o benchmark de suas funções com dados que refletem o que a função pode realmente operar no mundo real. Frequentemente uma função pode se comportar diferentemente em conjuntos menores de dados versus conjuntos grandes de dados! Isso é onde a configuração de input do Benchee entra. Isso permite que você teste a mesma função mas com muitas entradas diferentes conforme desejar, e então você pode ver os resultados do benchmark com cada uma dessas funções.
Então, vamos olhar nosso exemplo original novamente:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})No exemplo estamos usando apenas uma lista simples de inteiros de 1 à 10.000. Vamos atualizar isso para usar algumas entradas diferentes para que possamos ver o que acontece com listas menores e maiores. Então, abra o arquivo, e nós vamos mudá-lo para ficar assim:
map_fun = fn i -> [i, i * i] end
inputs = %{
"small list" => Enum.to_list(1..100),
"medium list" => Enum.to_list(1..10_000),
"large list" => Enum.to_list(1..1_000_000)
}
Benchee.run(
%{
"flat_map" => fn list -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn list -> list |> Enum.map(map_fun) |> List.flatten() end
},
inputs: inputs
)
Você notará duas diferenças. Primeiro, agora temos um mapa inputs que contém a informação para nossas entradas para nossas funções. Estamos passando aquele mapa de entradas como uma opção de configuração para Benchee.run/2.
E como nossas funções precisam de um argumento agora, precisamos atualizar nossas funções de benchmark para aceitar um argumento, então em vez de:
fn -> Enum.flat_map(list, map_fun) endagora temos:
fn list -> Enum.flat_map(list, map_fun) endVamos rodar isso novamente usando:
mix run benchmark.exsAgora você deve ver a saída no seu console como isso:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: large list, medium list, small list
Estimated total run time: 42 s
Benchmarking flat_map with input large list...
Benchmarking flat_map with input medium list...
Benchmarking flat_map with input small list...
Benchmarking map.flatten with input large list...
Benchmarking map.flatten with input medium list...
Benchmarking map.flatten with input small list...
##### With input large list #####
Name ips average deviation median 99th %
flat_map 13.20 75.78 ms ±25.15% 71.89 ms 113.61 ms
map.flatten 10.48 95.44 ms ±19.26% 96.79 ms 134.43 ms
Comparison:
flat_map 13.20
map.flatten 10.48 - 1.26x slower +19.67 ms
##### With input medium list #####
Name ips average deviation median 99th %
flat_map 2.66 K 376.04 μs ±23.72% 347.29 μs 678.17 μs
map.flatten 1.75 K 573.01 μs ±27.12% 512.48 μs 1076.27 μs
Comparison:
flat_map 2.66 K
map.flatten 1.75 K - 1.52x slower +196.98 μs
##### With input small list #####
Name ips average deviation median 99th %
flat_map 266.52 K 3.75 μs ±254.26% 3.47 μs 7.29 μs
map.flatten 178.18 K 5.61 μs ±196.80% 5.00 μs 10.87 μs
Comparison:
flat_map 266.52 K
map.flatten 178.18 K - 1.50x slower +1.86 μsAgora podemos ver informações para nossos benchmarks, agrupados por entrada. Este exemplo simples não fornece nenhuma intuição surpreendente, mas você ficaria bem surpreso o quanto a performance varia baseada no tamanho da entrada.
Formatadores
A saída do console que vimos é um começo útil para medir o tempo de execução de funções, mas não é sua única opção. Nessa seção vamos olhar brevemente os três formatadores disponíveis, e também tocar no que você vai precisar para escrever seu próprio formatador se quiser.
Outros formatadores
Benchee tem um formatador embutido para o console, que é o que já vimos, mas há outros três formatadores oficialmente suportados - benchee_csv, benchee_json e benchee_html. Cada um deles faz exatamente o que você esperaria, que é escrever os resultados no formato dos arquivos nomeados de forma que você possa trabalhar os resultados futuramente no formato que quiser.
Cada um desses formatadores é um pacote separado, então para usá-los você precisa adicioná-los como dependências no seu arquivo mix.exs como:
defp deps do
[
{:benchee_csv, "~> 1.0", only: :dev},
{:benchee_json, "~> 1.0", only: :dev},
{:benchee_html, "~> 1.0", only: :dev}
]
end
Enquanto benchee_json e benchee_csv são muito simples, benchee_html é na verdade muito completo! Ele pode ajudá-lo a produzir belos diagramas e gráficos de seus resultados facilmente, e você pode até mesmo exportá-los como imagens PNG. Você pode verificar um exemplo de relatório html se estiver interessado, ele inclui gráficos como este:
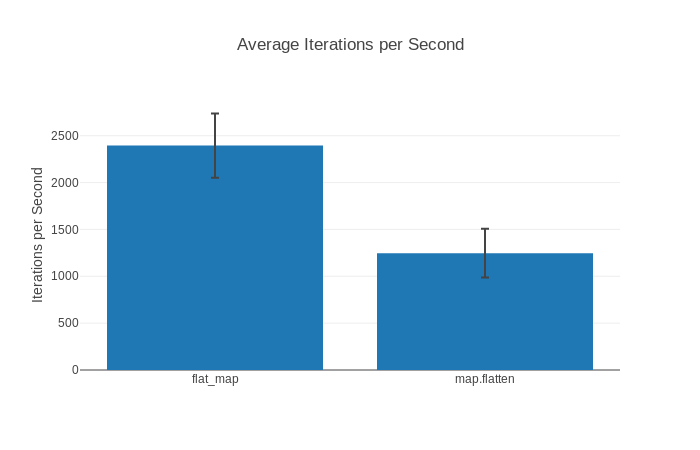
Todos os três formatadores são bem documentados nas suas respectivas páginas no GitHub, então não vamos cobrir todos os detalhes deles aqui.
Formatadores customizados
Se os quatro formatadores não são suficientes para você, você também pode escrever seu próprio formatador. Escrever um formatador é bem fácil. Você precisa escrever uma função que aceite uma estrutura %Benchee.Suite{}, e dela você pode tirar qualquer informação que você queira. Informação sobre o que exatamente está nessa estrutura pode ser encontrada no GitHub ou HexDocs. A base de código é bem documentada e fácil de ler se quiser ver quais tipos de informações podem estar disponíveis para escrever formatadores personalizados.
Você também pode escrever um formatador mais completo que adota o comportamento Benchee.Formatter vamos ficar com a versão da função mais simples aqui.
Por enquanto, vou mostrar um exemplo rápido de como um formatador customizado se pareceria como um exemplo de quão fácil ele é. Digamos que queremos um formatador mínimo que apenas imprima o tempo médio de cada cenário - isso é como ele se pareceria:
defmodule Custom.Formatter do
def output(suite) do
suite
|> format
|> IO.write()
suite
end
defp format(suite) do
Enum.map_join(suite.scenarios, "\n", fn scenario ->
"Average for #{scenario.job_name}: #{scenario.run_time_statistics.average}"
end)
end
endE então podemos rodar nosso benchmark desta forma:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
formatters: [&Custom.Formatter.output/1]
)E quando rodamos agora como nosso formatador customizado, veremos:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Average for flat_map: 419433.3593474056
Average for map.flatten: 788524.9366408596Memória
Estamos quase no fim, mas percorremos todo esse caminho sem mostrar a vocês uma das características mais legais do Benchee: medições de memória!
Benchee é capaz de medir o consumo de memória, é limitado ao processo em que seu benchmark é executado. Ele não pode monitorar o consumo de memória em outros processos (como pools de workers).
O consumo de memória inclui toda a memória que seu cenário de benchmarking usou - também a memória que foi coletada pelo garbage collector para que não represente necessariamente o tamanho máximo da memória do processo.
Como você pode usá-lo? Bem, você acabou de usar a opção :memory_time!
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 0 ns
time: 0 ns
memory time: 1 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking flat_map...
Benchmarking map.flatten...
Memory usage statistics:
Name Memory usage
flat_map 624.97 KB
map.flatten 781.25 KB - 1.25x memory usage +156.28 KB
**All measurements for memory usage were the same**Como você pode ver, Benchee não se importa em exibir todas as estatísticas com todas as amostras, elas foram as mesmas. Isso é muito comum se suas funções não incluem uma quantidade de aleatoriedade. E de que serviriam todas as estatísticas se lhe exibissem sempre os mesmos valores?
Caught a mistake or want to contribute to the lesson? Edit this lesson on GitHub!