Benchee
Невозможно угадать, какие функции работают быстро, а какие — медленно. Нам нужны настоящие измерения, получаемые при помощи тестирования производительности. В этом уроке мы узнаем, как легко измерять скорость нашего кода.
О Benchee
Несмотря на то, что в Erlang уже есть функция, которую можно использовать для простейших измерений времени выполнения кода, она не очень удобна по сравнению с некоторыми существующими инструментами, а также не поддерживает многократные измерения, необходимые для сбора полноценной статистики. Поэтому мы будем использовать Benchee.
Benchee позволяет нам использовать широкий набор метрик с возможностью легко сопоставлять результаты разных сценариев — что невероятно полезно при сравнении вызовов функций с несколькими наборами входных данных. Результаты можно красиво отобразить при помощи нескольких встроенных форматтеров, либо же написать свой собственный.
Использование
Чтобы использовать Benchee в своём проекте, просто добавим её в качестве зависимости в mix.exs:
defp deps do
[{:benchee, "~> 1.0", only: :dev}]
endТеперь вызовем:
$ mix deps.get
...
$ mix compile
Первая команда загрузит и установит Benchee.
Возможно, понадобится также установить Hex.
Вторая команда скомпилирует Benchee.
Всё готово к написанию нашего первого теста!
Важное замечание: тестируя производительность, очень важно не использовать интерактивный режим iex, поскольку он ведет себя иначе и зачастую гораздо медленнее того, что ваш код покажет в боевых условиях.
Давайте создадим файл benchmark.exs со следующим содержимым:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})Теперь, чтобы произвести замер производительности, исполним код в файле:
mix run benchmark.exsВ консоли должно появиться что-то похожее:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median 99th %
flat_map 2.40 K 416.00 μs ±12.88% 405.67 μs 718.61 μs
map.flatten 1.24 K 806.20 μs ±20.65% 752.52 μs 1186.28 μs
Comparison:
flat_map 2.40 K
map.flatten 1.24 K - 1.94x slower +390.20 μsРазумеется, ваша системная информация и результаты могут отличаться в зависимости от характеристик вашего компьютера. Но в целом вся эта информация должна быть представлена.
Взглянув на секцию Comparison, сразу становится понятно, что реализация map.flatten в 1,94 раз медленнее, чем flat_map. Также видно, что она в среднем на 390 микросекунд медленнее. Очень полезно! Но давайте взглянем и на другие метрики:
- ips — “итераций в секунду” — показывает, сколько раз функция успеет выполниться в течение одной секунды. Чем больше этот показатель, тем лучше.
- average — среднее — среднее время выполнения данной функции. Чем меньше, тем лучше.
- deviation — отклонение — значение стандартного отклонения. Показывает, насколько результаты каждой отдельной итерации отличаются от среднего. Измеряется в процентах от среднего значения.
- median — медиана — если отсортировать все замеры, медиана будет центральным значением (или средним из двух центральных, если количество измерений чётное). Из-за изменчивости окружения, медиана — более стабильный показатель, чем среднее значение. К тому же она надежнее отразит поведение вашего кода в боевых условиях. Чем меньше медиана, тем лучше.
- 99th % - 99% всех замеров быстрее этого, что в какой-то степени делает его показателем худшей производительности. Чем меньше, тем лучше.
Существуют также другие метрики, но на эти пять, как правило, обращают наибольшее внимание при тестировании производительности, поэтому они выводятся в результатах стандартным форматтером. Узнать больше о других метриках можно в документации.
Настройка
Одна из лучших сторон Benchee — это большое количество настроек.
Мы пройдемся сперва по простейшим из них, т.к. они понятны даже без примеров кода. Затем мы посмотрим, как использовать одну из самых крутых возможностей Benchee — наборы входных данных.
Основы
Benchee использует для настройки параметры конфигурации. В основном интерфейсе Benchee.run/2 они передаются вторым аргументом в виде опционального ключевого списка.
Benchee.run(
%{"example function" => fn -> "hi!" end},
warmup: 4,
time: 10,
inputs: nil,
parallel: 1,
formatters: [&Benchee.Formatters.Console.output/1],
print: [
benchmarking: true,
configuration: true,
fast_warning: true
],
console: [
comparison: true,
unit_scaling: :best
]
)Список доступных параметров (также описан в документации):
- warmup — прогрев — время в секундах, в течение которого сценарий будет выполняться “в холостую”, прежде чем начнутся реальные замеры производительности. Это имитирует “прогрев” реальной системы. Значение по умолчанию — 2.
- time — время в секундах, в течение которого каждый отдельный сценарий будет исполняться с выполнением измерений. По умолчанию равно 5.
- memory_time — время в секундах, в течении которого будет замеряться потребление памяти для каждого отдельного сценария. We’ll look at that later. Defaults to 0.
-
inputs — ассоциативный массив со строками, в котором ключи отвечают за название параметра, а значения — за сами передаваемые параметры. Также может быть списком кортежей в форме
{input_name, actual_value}По умолчанию равноnil(нет параметров). Мы детальнее опишем этот пункт в следующей секции. -
parallel — количество процессов, которое следует использовать при тестировании.
Так, если мы передадим
parallel: 4, то создадутся 4 процесса, каждый из которых будет выполнять одну и ту же функцию на протяженииtimeсекунд. Когда они закончат, 4 новых процесса будут запущены уже для следующей функции. Это позволит собрать больше данных за то же время, но при этом создаст некоторую нагрузку на систему, что может повлиять на результаты. Этот параметр можно использовать для симуляции системы под нагрузкой, что иногда полезно. Однако надо помнить, что параллельное выполнение может непредсказуемо повлиять на результаты, так что использовать его нужно с осторожностью. Значение по умолчанию: 1 (т.е. без параллельного выполнения). -
formatters — форматтеры — список форматтеров (модулей с поведением форматтера, кортежа с таким модулем и опциями, которые он принимает, либо функций форматирования) который вы бы хотели использовать для отображения результата выполнения
Benchee.run/2. Функции должны принимать один аргумент (набор данных) и затем с его помощью отображать результат. По умолчанию используется встроенный консольный форматтерBenchee.Formatters.Console.output/1. Мы подробнее рассмотрим форматтеры чуть позже. -
measure_function_call_overhead - замеряет время, которое занимает вызов пустой функции, и отнимает его от времени каждого замера. Помогает с точностью очень быстрых замеров. По умолчанию
true. -
pre_check - определяет, запускать ли каждую пару “замер - ввод” - включая все сценарии
before,afterи хуки - прежде чем проводить замеры, чтобы убедиться, что ваш код запустится без ошибок. Это экономит время при написании замеров. По умолчаниюfalse. -
save - определяет путь (
path) для хранения результатов текущего набора замеров, с пометкой специальным тегом (tag). См. раздел Сохранение и загрузка в документации Benchee. - load - загружает сохранённый набор(ы) замеров для сравнения с текущими. Может быть строкой или списком строк или паттернов. См. раздел Сохранение и загрузка в документации Benchee.
-
print — ассоциативный массив или ключевой список со следующими опциями-атомами в качестве ключей и
trueилиfalseв качестве значений. С помощью этого параметра мы можем указывать, какие метрики должны быть выведены в ходе стандартного выполнения теста. Все опции включены по умолчанию (имеют значениеtrue). Вот они:-
benchmarking — выводится, когда
Bencheeзапускает новый тест. - configuration — краткий список всех настроек, включая прогнозируемое время выполнения. Выводится перед началом теста.
- first_warning — предупреждения выводятся в случае, если функция выполняется слишком быстро, что потенциально может привести к неточным результатам.
-
benchmarking — выводится, когда
-
unit_scaling — масштабирование — стратегия выбора единиц измерения для времени и количества.
Когда масштабирование включено,
Bencheeподыщет наиболее подходящее отображение для чисел. Например,1_200_000масштабируется в 1,2 М, а800_000в 800 К. Стратегия масштабирования определяет то, какBencheeбудет выбирать отображение числовых значений в случаях, когда “наилучший” вид разный для разных чисел. Всего есть четыре стратегии, у каждой — имя-атом. По умолчанию используется:best:- best — будет выбрано наиболее часто встречающееся сокращение. В случае совпадения, будет выбрано наибольшее.
- largest — среди наилучших сокращений будет выбрано наибольшее.
- smallest — среди наилучших будет выбрано наименьшее.
-
none — масштабирование не будет использоваться вовсе.
Время будет выводится в наносекундах, а количество
ips— без тысячных сокращений.
-
:before_scenario/after_scenario/before_each/after_each- мы не будем углубляться в эти опции здесь, но если вам нужно что-то сделать перед/после вашей функции замера, не включая это в замер, обратитесь к документации о хуках в Benchee
Наборы входных данных
Очень важно тестировать функции с использованием данных, похожих на те, с которыми они скорее всего столкнутся в реальном мире.
Часто функция может вести себя по-разному на маленьких и больших наборах данных. Специально для таких случаев Benchee поддерживает наборы входных данных (inputs)!
Они позволяют нам тестировать одну и ту же функцию со столькими наборами входных данных, сколько нам понадобится, а затем отобразить их в результатах.
Посмотрим на наш первый пример:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
})В нём мы используем один-единственный список целых чисел от 1 до 10 000. Давайте вместо него используем несколько разных аргументов, чтобы можно было сравнить результаты на малых и больших списках. Должно получиться так:
map_fun = fn i -> [i, i * i] end
inputs = %{
"small list" => Enum.to_list(1..100),
"medium list" => Enum.to_list(1..10_000),
"large list" => Enum.to_list(1..1_000_000)
}
Benchee.run(
%{
"flat_map" => fn list -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn list -> list |> Enum.map(map_fun) |> List.flatten() end
},
inputs: inputs
)
Можно заметить два существенных различия.
Во-первых, мы создали ассоциативный массив inputs, в котором хранится информация о наборах входных данных.
Во-вторых, мы передаём его в виде настройки в Benchee.run/2.
И так как теперь наша функция должна уметь принимать входной аргумент, мы должны заменить:
fn -> Enum.flat_map(list, map_fun) endна:
fn(list) -> Enum.flat_map(list, map_fun) endСнова запустим наши измерения:
mix run benchmark.exsТеперь должно получиться что-то такое:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: large list, medium list, small list
Estimated total run time: 42 s
Benchmarking flat_map with input large list...
Benchmarking flat_map with input medium list...
Benchmarking flat_map with input small list...
Benchmarking map.flatten with input large list...
Benchmarking map.flatten with input medium list...
Benchmarking map.flatten with input small list...
##### With input large list #####
Name ips average deviation median 99th %
flat_map 13.20 75.78 ms ±25.15% 71.89 ms 113.61 ms
map.flatten 10.48 95.44 ms ±19.26% 96.79 ms 134.43 ms
Comparison:
flat_map 13.20
map.flatten 10.48 - 1.26x slower +19.67 ms
##### With input medium list #####
Name ips average deviation median 99th %
flat_map 2.66 K 376.04 μs ±23.72% 347.29 μs 678.17 μs
map.flatten 1.75 K 573.01 μs ±27.12% 512.48 μs 1076.27 μs
Comparison:
flat_map 2.66 K
map.flatten 1.75 K - 1.52x slower +196.98 μs
##### With input small list #####
Name ips average deviation median 99th %
flat_map 266.52 K 3.75 μs ±254.26% 3.47 μs 7.29 μs
map.flatten 178.18 K 5.61 μs ±196.80% 5.00 μs 10.87 μs
Comparison:
flat_map 266.52 K
map.flatten 178.18 K - 1.50x slower +1.86 μsМы видим результаты замеров, сгруппированные по входным данным. В этом простом примере не видно никакой гигантской разницы, но в реальном мире производительность может о-о-очень отличаться в зависимости от размера данных.
Форматтеры
Консольный вывод, который мы видели прежде, — отличное начало, но это не единственный доступный вариант. В этой секции мы взглянем на три других форматтера, а также узнаем, что нужно сделать, чтобы написать свой.
Другие форматтеры
Помимо консольного форматтера, существует еще три -
benchee_csv,
benchee_json и
benchee_html.
Все они делают именно то, что можно было бы ожидать исходя из их названия: пишут результат в файлы соответствующего формата, чтобы затем с ними можно было работать любым удобным способом.
Каждый из этих форматтеров поставляется отдельным пакетом, поэтому, для использования, их нужно добавить в качестве зависимостей в mix.exs:
defp deps do
[
{:benchee_csv, "~> 1.0", only: :dev},
{:benchee_json, "~> 1.0", only: :dev},
{:benchee_html, "~> 1.0", only: :dev},
]
end
В то время как benchee_json и benchee_csv очень просты, benchee_html можно назвать крайне продвинутым!
Он может с легкостью строить красивые графики и диаграммы, и даже позволяет экспортировать их в изображение формата PNG.
Можете посмотреть пример вывода html, если интересно - он включает в себя графики вроде этого:
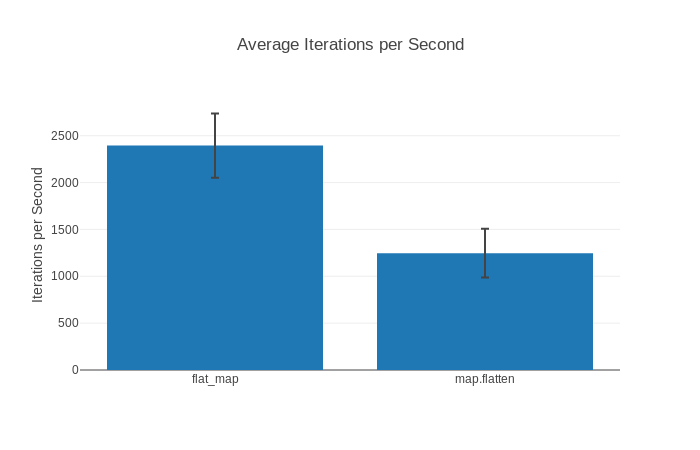
Для всех трёх форматтеров написана хорошая документация на их страницах на GitHub, поэтому мы не будем вдаваться в детали.
Собственные форматтеры
Если ни один из имеющихся форматтеров не подходит, всегда можно написать собственный.
Сделать это несложно.
Надо написать функцию, которая будет принимать структуру %Benchee.Suite{}, из которой она в дальнейшем будет доставать любую нужную информацию.
Подробнее о том, что именно находится в структуре, можно почитать на GitHub или в HexDocs.
Код очень хорошо документирован и легко читается, полезно, чтобы знать, какого рода информация доступна для написания собственных форматтеров.
Вы также можете написать более полноценный форматтер, который реализует поведение Benchee.Formatter, но тут мы остановимся на простой функции.
Для примера продемонстрируем, как можно легко и быстро написать собственный форматтер. Предположим, что мы хотим супер-минималистичный форматтер, который просто выводит среднее время выполнения для каждого сценария. Это будет выглядеть примерно так:
defmodule Custom.Formatter do
def output(suite) do
suite
|> format
|> IO.write()
suite
end
defp format(suite) do
Enum.map_join(suite.scenarios, "\n", fn scenario ->
"Average for #{scenario.job_name}: #{scenario.run_time_statistics.average}"
end)
end
endИ теперь запустим измерения:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
formatters: [&Custom.Formatter.output/1]
)Наш форматтер должен вывести следующее:
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Average for flat_map: 419433.3593474056
Average for map.flatten: 788524.9366408596Память
Мы почти всё рассмотрели, но обошли стороной одну из крутейших возможностей Benchee: замеры памяти!
Benchee может измерять потребление памяти, но имея доступ только к процессу, в котором запущен замер. Сейчас Benchee не может отслеживать потребление памяти другими процессами (к примеру, пулами воркеров).
Потребление памяти включает всю память, использованную вашими замерами, и также память, которая была освобождена сборщиком мусора, так что не обязательно соответствует максимальному размеру памяти процесса.
Как этим пользоваться? Просто используйте опцию :memory_time!
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.3.2
Benchmark suite executing with the following configuration:
warmup: 0 ns
time: 0 ns
memory time: 1 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking flat_map...
Benchmarking map.flatten...
Memory usage statistics:
Name Memory usage
flat_map 624.97 KB
map.flatten 781.25 KB - 1.25x memory usage +156.28 KB
**All measurements for memory usage were the same**Как видите, Benchee не пытается отобразить все метрики, так как все собранные замеры одинаковые. На самом деле, так часто бывает, если ваши функции не подвергаются случайности в том или ином виде. И какой прок был бы от всех этих метрик, если бы они выдавали одну и ту же цифру каждый раз?
Caught a mistake or want to contribute to the lesson? Edit this lesson on GitHub!